Kevin Meng
currently: @transluce
contact: kevin [at] transluce [dot] org
location: san francisco (sometimes boston)
my interests:
- ai interpretability
- information retrieval
- databases
- data visualization
currently: @transluce
contact: kevin [at] transluce [dot] org
location: san francisco (sometimes boston)
hi, i'm kevin! 👋
i am a founding member of transluce, a new research lab that builds open-source technology to understand and control AI systems. i have long been interested in interpretability and used to work on this problem in academia with collaborators from mit, northeastern, and harvard.
aside from work, i care deeply about education. back at home, i ran a non-profit providing mentorship to aspiring scientists, where i still occasionally volunteer. at mit, i organized lots of ai workshops and taught for splash. in my free time, i enjoy long walks, road trips, running very slowly, getting cooked in basketball, making inedible food, idly shuffling cards, and aimlessly wandering the streets of new cities. i used to make music and miss it a lot.
i received my bs/ms from mit in electrical engineering, computer science, and artificial intelligence.
Publication
|
Code
|
Project Page
Kevin Meng,
Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, David Bau
*Presented at ICLR 2023 in Kigali, Rwanda
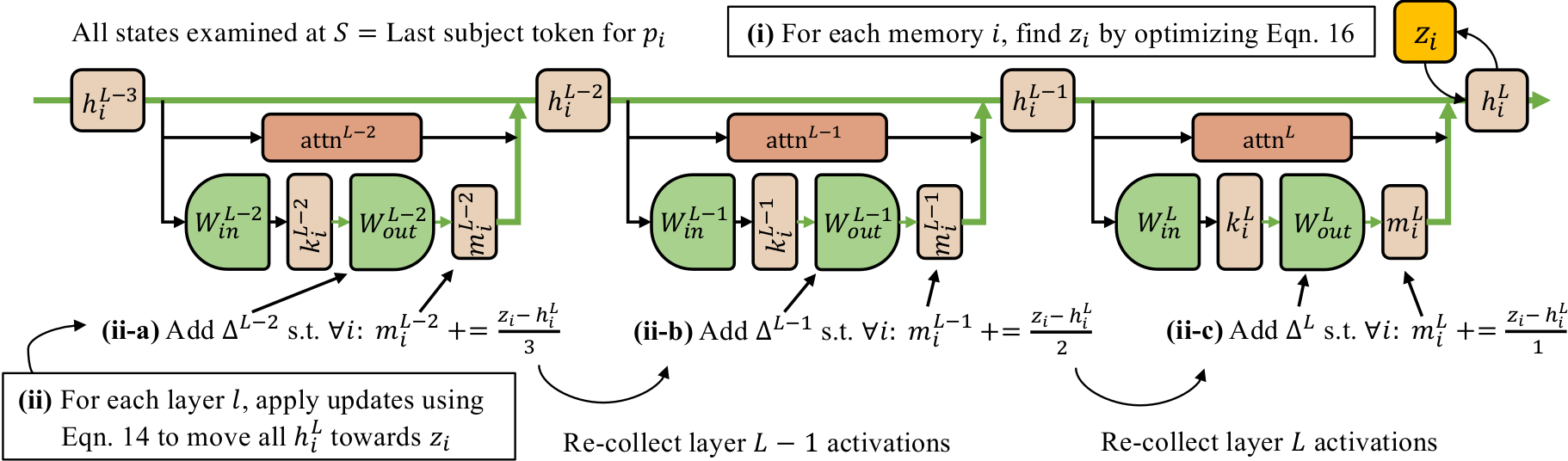
Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limited to updating single associations. We develop MEMIT, a method for directly updating a language model with many memories, demonstrating experimentally that it can scale up to thousands of associations for GPT-J (6B) and GPT-NeoX (20B), exceeding prior work by orders of magnitude.
Publication
|
Code
|
Project Page
Kevin Meng*,
David Bau*, Alex Andonian, Yonatan Belinkov
*Presented at NeurIPS 2022 in New Orleans, LA
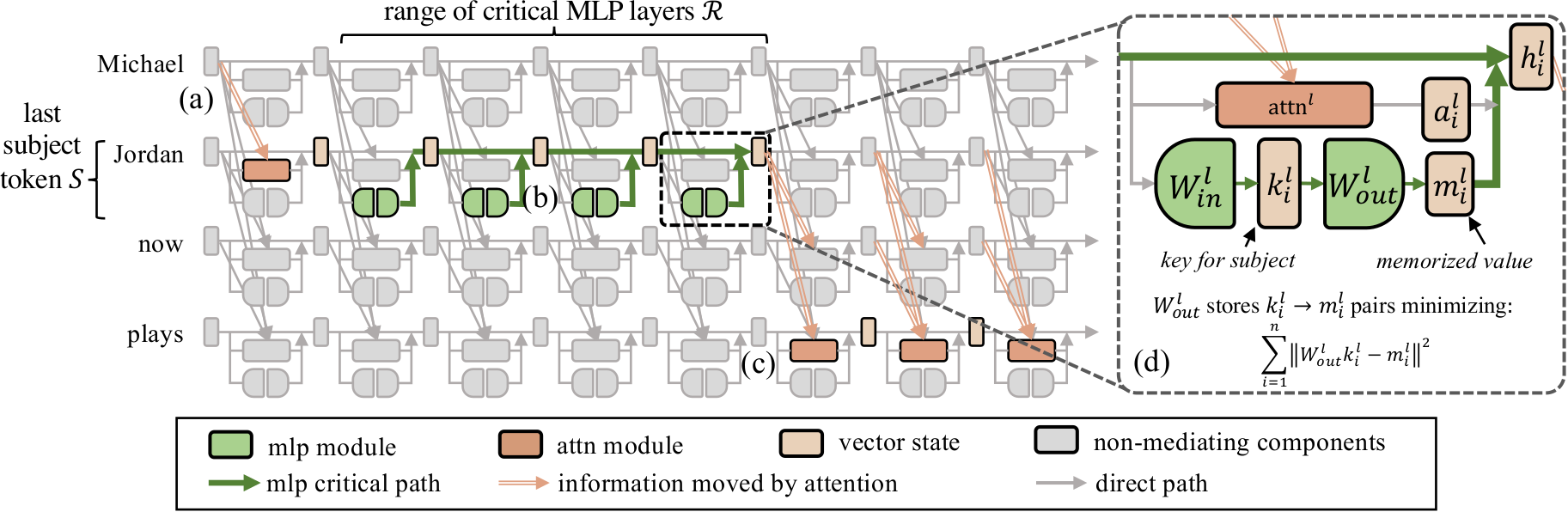
We investigate the mechanisms underlying factual knowledge recall in autoregressive transformer language models. First, we develop a causal intervention for identifying neuron activations capable of altering a model's factual predictions. Within large GPT-style models, this reveals two distinct sets of neurons that we hypothesize correspond to knowing an abstract fact and saying a concrete word, respectively. This insight inspires the development of ROME, a novel method for editing facts stored in model weights. For evaluation, we assemble CounterFact, a dataset of over twenty thousand counterfactuals and tools to facilitate sensitive measurements of knowledge editing. Using CounterFact, we confirm the distinction between saying and knowing neurons, and we find that ROME achieves state-of-the-art performance in knowledge editing compared to other methods. An interactive demo notebook, full code implementation, and the dataset are available.

Publication
Jagdeep Bhatia*,
Kevin Meng*
*Presented at ICML 2022's ML for Cybersecurity Workshop in
Baltimore, MD
Perceptual hashes map images with identical semantic content to the same n-bit hash value, while mapping semantically-different images to different hashes. These algorithms carry important applications in cybersecurity such as copyright infringement detection, content fingerprinting, and surveillance. Apple's NeuralHash is one such system that aims to detect the presence of illegal content on users' devices without compromising consumer privacy. We make the surprising discovery that NeuralHash is approximately linear, which inspires the development of novel black-box attacks that can (i) evade detection of "illegal" images, (ii) generate near-collisions, and (iii) leak information about hashed images, all without access to model parameters. These vulnerabilities pose serious threats to NeuralHash's security goals; to address them, we propose a simple fix using classical cryptographic standards.

Publication
|
Claim-Spotter Paper
|
Demo Video
Kevin Meng
*Presented at NeurIPS 2021's Workshop on AI for Credible
Elections
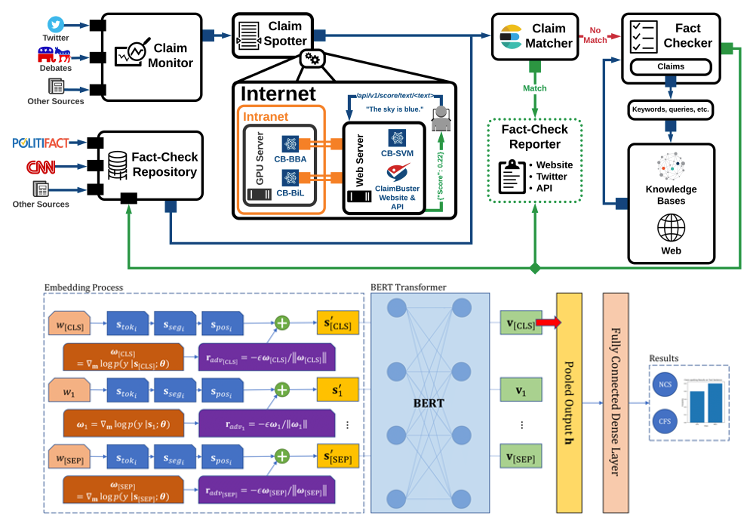
VeriClaim contains two computational modules: the claim-spotter and claim-checker. The claim-spotter first selects “check-worthy” factual statements from large amounts of text using a Bidirectional Encoder Representations from Transformers (BERT) model trained with a novel gradient-based adversarial training algorithm. Then, selected factual statements are passed to the claim-checker, which employs a separate stance detection BERT model to verify each statement using evidence retrieved from a multitude of knowledge resources. Web interface inspired by Fakta, from MIT.

Publication
|
Code
|
Data
|
Dashboard
|
Demo Video
Zhengyuan Zhu,
Kevin Meng, Josue
Caraballo, Israa Jaradat, Xiao Shi, Zeyu Zhang, Farahnaz
Akrami, Haojin Liao, Fatma Arslan, Damian Jimenez, Mohammed
Samiul Saeef, Paras Pathak, Chengkai Li
This paper introduces a public dashboard which, in addition to displaying case counts in an interactive map and a navigational panel, also provides some unique features not found in other places. Particularly, the dashboard uses a curated catalog of COVID-19 related facts and debunks of misinformation, and it displays the most prevalent information from the catalog among Twitter users in user-selected U.S. geographic regions. We also explore the usage of BERT models to match tweets with misinformation debunks and detect their stances. We also discuss the results of preliminary experiments on analyzing the spatio-temporal spread of misinformation.
Pre-Print
|
Code
|
ClaimBuster Website
Kevin Meng*, Damian
Jimenez*, Fatma Arslan, Jacob Daniel Devasier, Daniel Obembe,
Chengkai Li
*Deployed on
ClaimBuster, used by thousands of fact-checkers and research groups
worldwide
We introduce the first adversarially-regularized, transformer-based claim spotting model that achieves state-of-the-art results by a 4.70 point F1-score margin over current approaches on the ClaimBuster Dataset. In the process, we propose a method to apply adversarial training to transformer models, which has the potential to be generalized to many similar text classification tasks. Along with our results, we are releasing our codebase and manually labeled datasets. We also showcase our models' real world usage via a live public API.